FPGA Programming – Increase Speed and Save Resources with Simple Coding Style Changes
ASIC vs. FPGA in Process Acceleration
Compared to ASICs, FPGAs are a much more versatile option when it comes to accelerating processes with hardware, as an FPGA can be reconfigured and programmed as often as needed.
However, one large benefit to ASICs is the possible maximum clock speed that can be reached. As its circuit is optimized for its specific function, it has a smaller footprint, resulting in a faster maximum clock speed.
So one aspect of accelerating a process with FPGAs is not only just to redesign that process in hardware and hoping for faster results, but to smartly redesign that process to use as little hardware space as possible, resulting in a higher maximum clock speed.
As engineers we know, there is always room for improvement, so we at Missing Link Electronics strive to continuously improve our existing product lineup.
MLE Smart Process Redesign in FPGA Programming for Resource Saving and Speed Increasing
In one of these development cycles, we encountered a simple, yet very effective improvement of the synchronous reset logic hardware descriptions in our TCP/UDP/IP Network Protocol Accelerator (NPAP).
Up to that point, the reset logic in pretty much all of our modules was described like this:


At the clock cycle, we handled the reset inside an if-statement, whereas all other logic was treated in the other case.
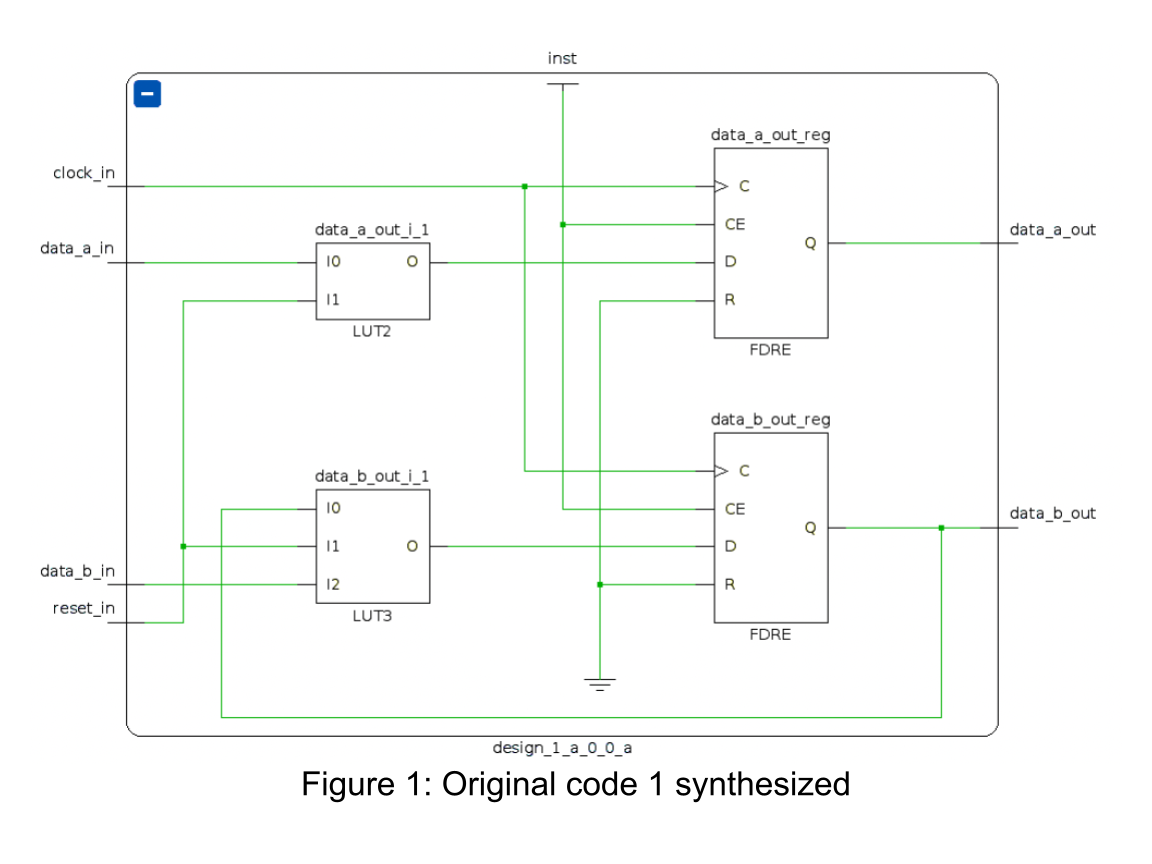
That specific code is synthesized by Vivado 2020.2 to the schematic shown in Figure 1.
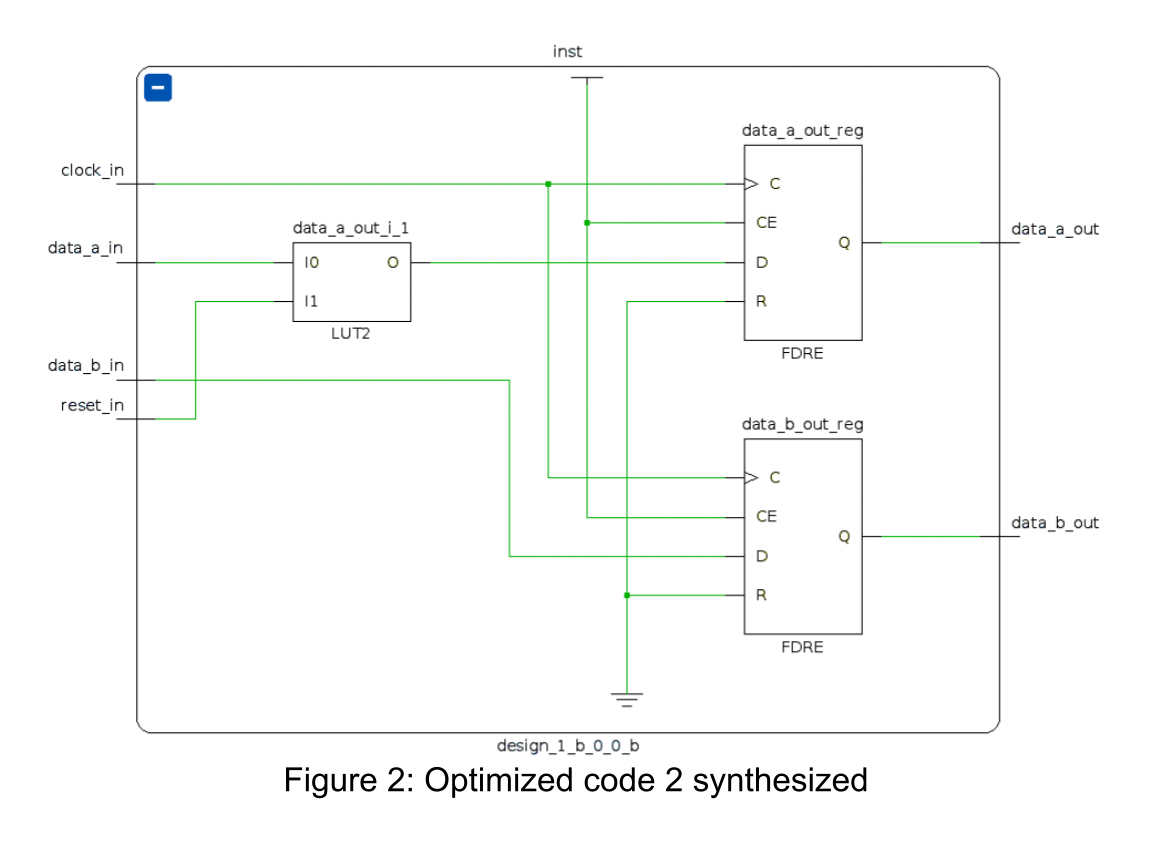
Now looking at Code 2, semantically speaking the code does almost the same. The reset is still handled inside the if-statement, however, all other logic is handled before the reset case. Looking at the synthesized result of that code in Figure 2, we see that by just removing the else statement, we also removed a whole LUT from the design! And thinking how we only used two LUTs in that example, we just shaved off 50% of our LUT usage! Isn’t that amazing?
And this does not only work in Vivado, but in Libero SoC and Quartus Prime as well – we tested it!
How can this work? As seen in the code, the data_b_out register is not affected by the reset at all. The difference between the code samples in case of a reset is that in Code 2, the data_b_out register is still set to the data_b_in register, whereas in Code 1, the data_b_out register is not touched at all, so it stays the same. And it is this “staying the same” which is the reason for the extra LUT, as the synthesizer creates a feedback loop from data_b_out to be used as an input for the data_b_out register in case of a reset.
So depending on how many of these structures you have, you might be able to reduce your hardware footprint and increase your maximum frequency by quite a lot.
In our specific use case with NPAP, we were able to go from using 127096 LUTs to using 122228 LUTs, which is a decrease in LUT usage of almost 4%!
So in the future, keep in mind that coding style not only affects readability, but can also affect hardware usage and speed of the synthesized design.
Our Mission: If It Is Packets, We Make It Go Faster!
And with packets we mean: Networking using TCP/UDP/IP over 10G/25G/50G/100G Ethernet; PCI Express (PCIe), CXL, OpenCAPI; data storage using SATA, SAS, USB, NVMe; video image processing using HDMI, DisplayPort, SDI, FPD-III.
Over the last decade, we have become experts in accelerating software-rich system stacks via offloading CPUs using so-called Domain-Specific Architectures for computing. For implementation, we make heavy use of heterogeneous processing devices such as FPGAs which we program using C++/C/SystemC as well as VHDL and Verilog HDL.
🌐 www.missinglinkelectronics.com
MLE (Missing Link Electronics) is offering technologies and solutions for Domain-Specific Architectures, which focus on heterogeneous computing using FPGAs. MLE is headquartered in Silicon Valley with offices in Neu-Ulm and Berlin, Germany.